ChatGPT の API に logprobs なるパラメータがあることを最近知った(参考: https://platform.openai.com/docs/api-reference/chat/create)。これは、GPT のトークンごとの出力確率を表示できるオプションで、 response.choices[0].logprobs.content 内に次のような値が出力される。
[ChatCompletionTokenLogprob(token='どう', bytes=[227, 129, 169, 227, 129, 134], logprob=-0.9088138, top_logprobs=[]),
ChatCompletionTokenLogprob(token='や', bytes=[227, 130, 132], logprob=-0.54998726, top_logprobs=[]),
ChatCompletionTokenLogprob(token='ら', bytes=[227, 130, 137], logprob=-5.3239244e-05, top_logprobs=[]),
ChatCompletionTokenLogprob(token='\\xe6\\x9b', bytes=[230, 155], logprob=-1.8661908, top_logprobs=[]),
ChatCompletionTokenLogprob(token='\\x87', bytes=[135], logprob=-6.704273e-07, top_logprobs=[]),
ChatCompletionTokenLogprob(token='り', bytes=[227, 130, 138], logprob=-0.00022940392, top_logprobs=[]),
ChatCompletionTokenLogprob(token='の', bytes=[227, 129, 174], logprob=-0.5894802, top_logprobs=[]),
ChatCompletionTokenLogprob(token='ち', bytes=[227, 129, 161], logprob=-0.18024994, top_logprobs=[]),
ChatCompletionTokenLogprob(token='雨', bytes=[233, 155, 168], logprob=-0.22814354, top_logprobs=[]),
ChatCompletionTokenLogprob(token='の', bytes=[227, 129, 174], logprob=-0.67014575, top_logprobs=[]),
ChatCompletionTokenLogprob(token='予', bytes=[228, 186, 136], logprob=-0.001581282, top_logprobs=[]),
ChatCompletionTokenLogprob(token='報', bytes=[229, 160, 177], logprob=-0.0010872321, top_logprobs=[]),
ChatCompletionTokenLogprob(token='です', bytes=[227, 129, 167, 227, 129, 153], logprob=-0.5530148, top_logprobs=[])]response = openai.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "ユーザーが入力した文章の続きを、ユーザーの代わりに生成してください。"},
{"role": "user", "content": "ますます蒸し暑くなりそうです。明日の天気は"},
],
max_tokens=50,
logprobs=True,
temperature=0,
stop=["。"],
)logprobs=True に着目トークンごとに ChatCompletionTokenLogprob オブジェクトが生成され、 logprob に対数確率の値が入っている。 top_logprobs は空だが、リクエストに top_logprobs パラメータを指定することで、次トークンの他の候補を見ることができる。
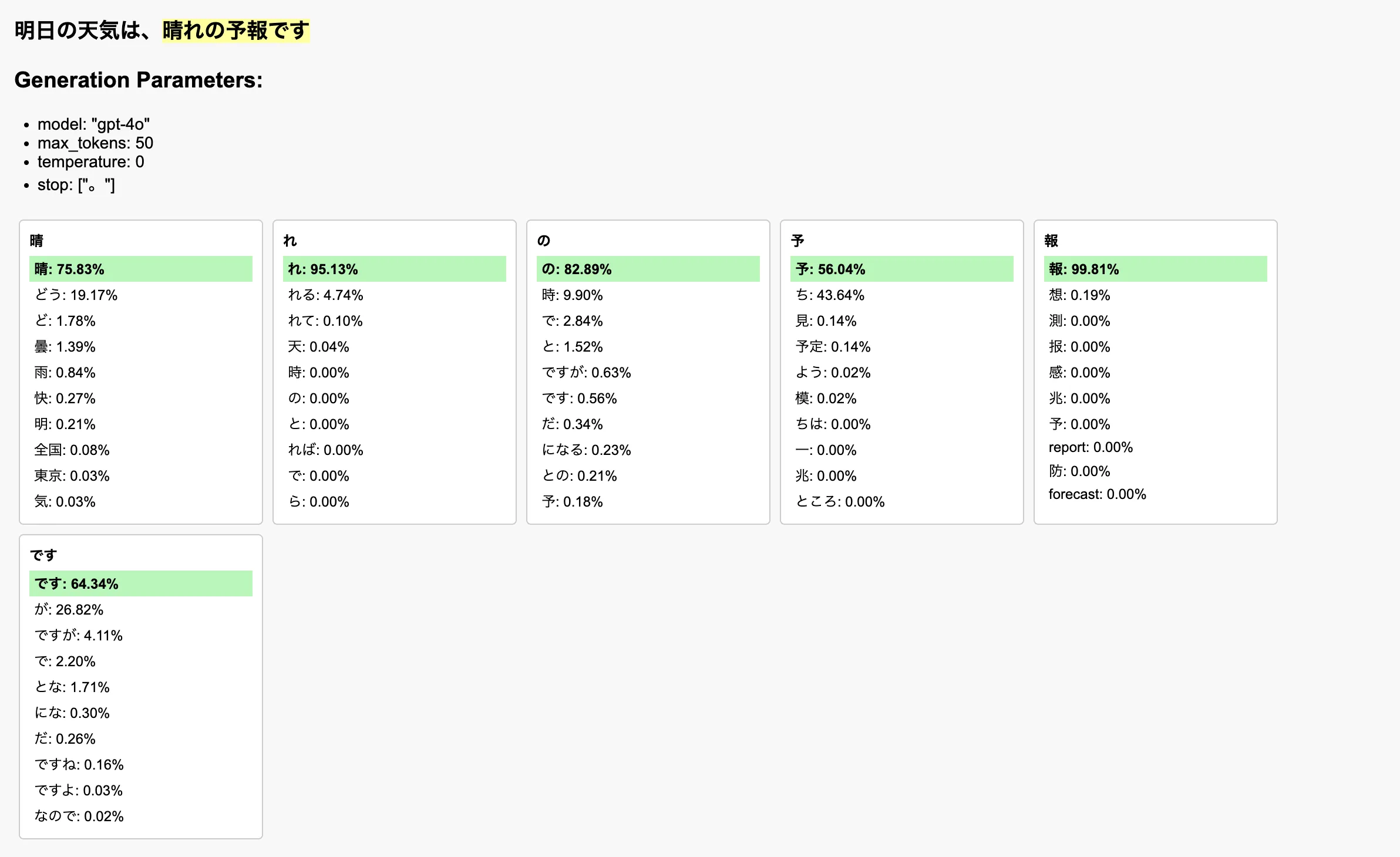
これを用いて、例えば次のようにLLMが次トークンを文脈に応じて決定していく様子を可視化することができる。LLMの内部動作はブラックボックスっぽく扱われがちで、その様子をイメージできる人はそう多くないイメージだが、これを眺めると少し理解の助けになるのではないか。
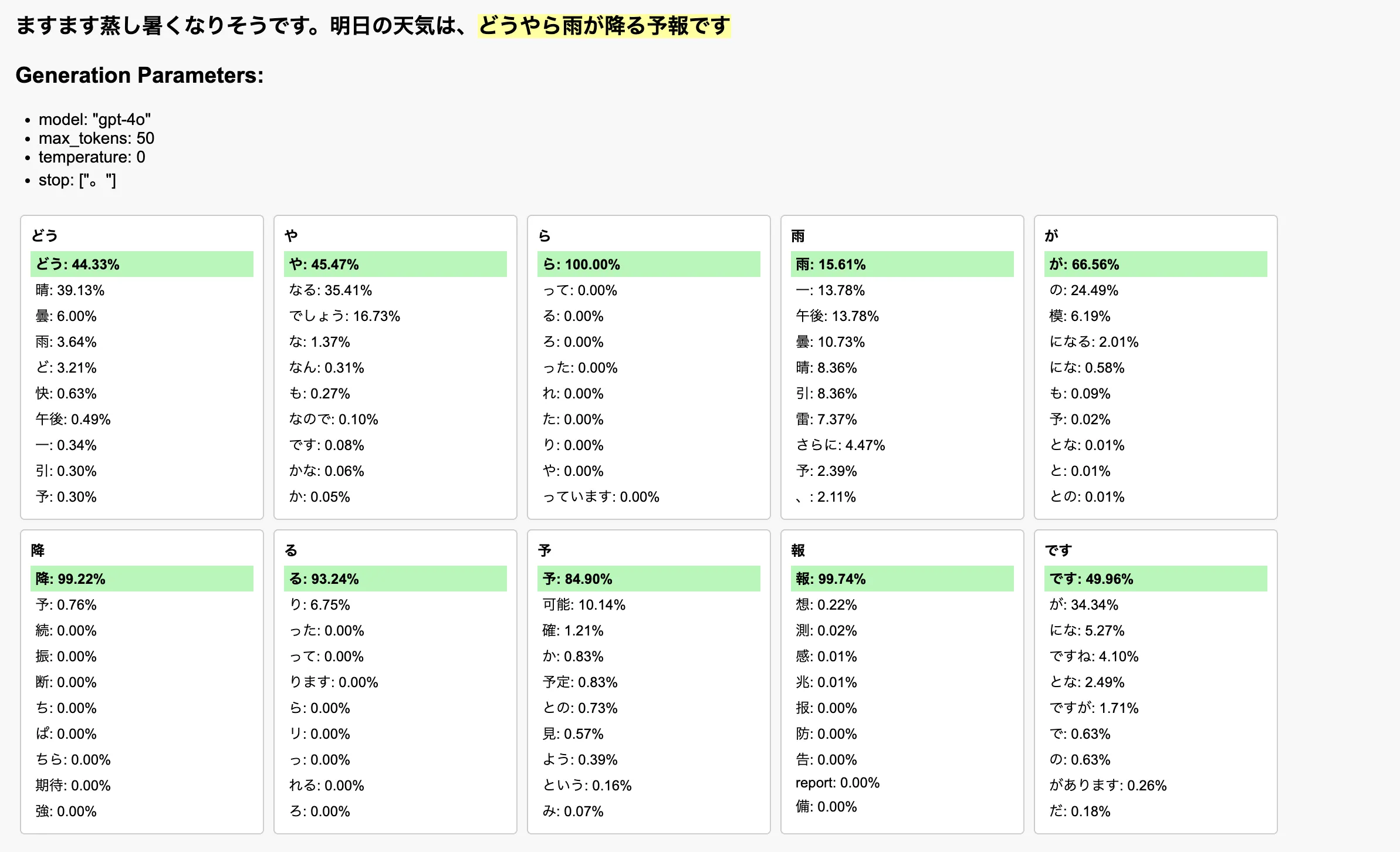
文脈を変えてみると、現れる候補と確率も変わってくることが次の図によってわかる。
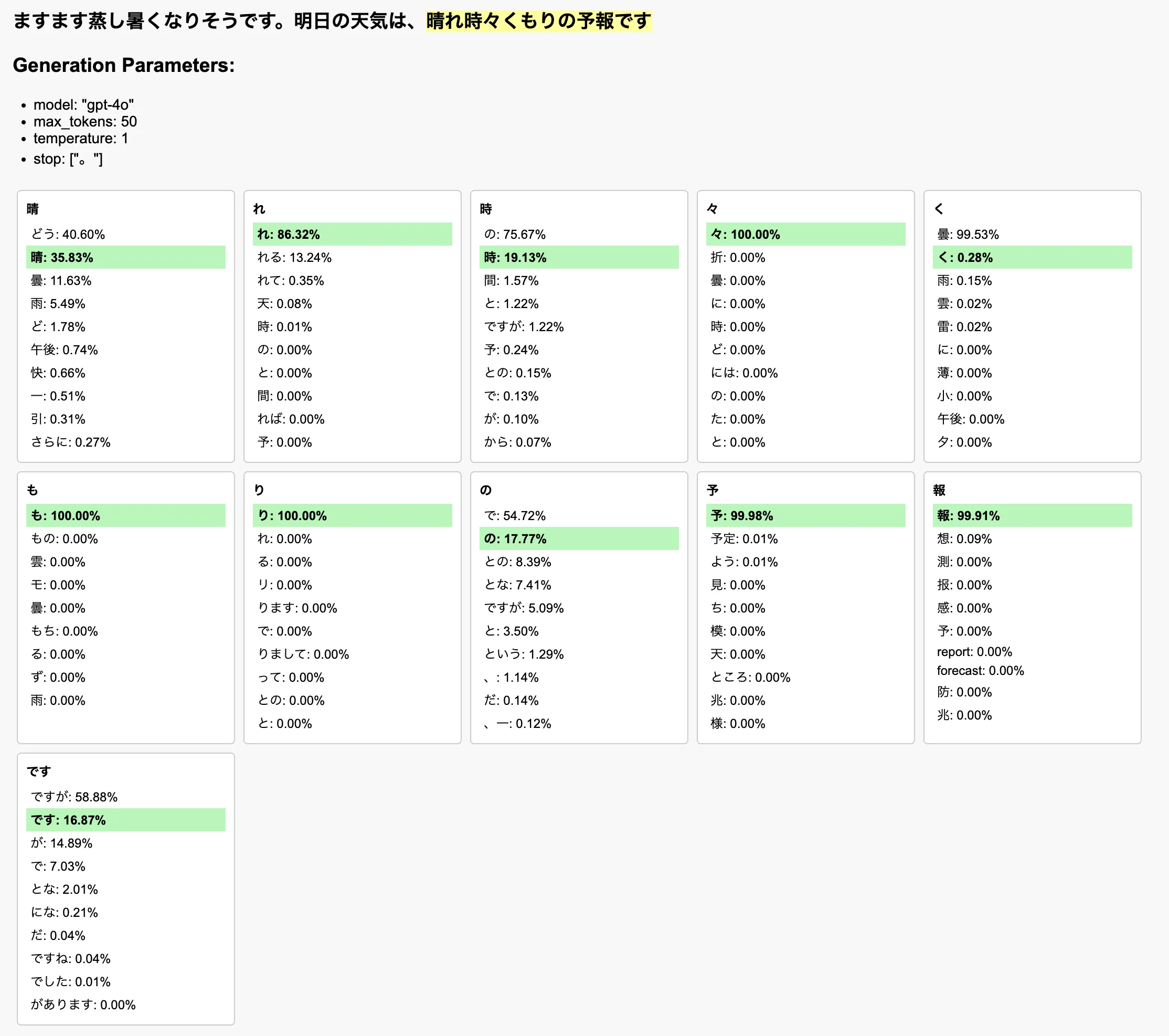
temperature を大きくすると、出力のランダム性が高まり、確率が最大のトークンを選択するとは限らなくなる。これを可視化したのが↓
ちなみにこの可視化は Claude の Artifacts にやってもらった。レスポンスをそのまま投げて「以下のデータをもとに、LLMに文章の続きを生成させたときのトークンごとの選択肢と確率を可視化して、LLMの挙動を解説できる図を作成したいです」のような指示を送って何度か対話をしていく中で、勝手に作ってくれたやつ。
「単一のHTMLファイルにエクスポートして」と言ったら出力してくれるし、HTMLだったら値をあとから編集したり、細かい調整が出来る。本当に便利な世の中になっちゃったね。
このような可視化を通してLLMの挙動への理解を深めることは、LLMと付き合っていくうえで大事な取り組みだと思う。みんなもやってみよう!